Chapter 21 Data Processing Architectures
The difficulty in life is the choice.
George Moore, The Bending of the Bough, 1900
Learning Objectives
Students completing this chapter will be able to - recommend a data architecture for a given situation; - understand multi-tier client/server architecture; - discuss the fundamental principles that a hybrid architecture should satisfy; - demonstrate the general principles of distributed database design.
Architectural choices
In general terms, data can be stored and processed locally or remotely. Combinations of these two options provide the basic information systems architectures.
Basic architectures
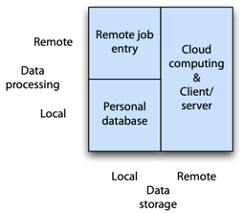
Remote job entry
In remote job entry, data are stored locally and processed remotely. Data are sent over a network to a remote computer cluster for processing, and the output is returned the same way. Remote job entry can overcome speed or memory shortcomings of a personal computer. Scientists and engineers typically need occasional access to a supercomputer for applications, such as simulating global climate change, that are data or computational intensive. Clusters typically have the main memory and processing power to handle such problems.
Local storage is used for several reasons. First, it may be cheaper than storing on a cluster. Second, the analyst might be able to do some local processing and preparation of the data before sending them to the cluster. Cluster time can be expensive. Where possible, local processing is used for tasks such as data entry, validation, and reporting. Third, local data storage might be deemed more secure for particularly sensitive data.
Personal database
People can store and process their data locally when they have their own computers. Many personal computer database systems (e.g., MS Access and FileMaker) permit people to develop their own applications, and many common desktop applications require local database facilities (e.g., a calendar).
Of course, there is a downside to personal databases. First, there is a great danger of repetition and redundancy. The same application might be developed in a slightly different way by many people. The same data get stored on many different systems. (It is not always the same, however, because data entry errors or maintenance inconsistencies result in discrepancies between personal databases.) Second, data are not readily shared because people are not always aware of what is available or find it inconvenient to share data. Personal databases are exactly that; but much of the data may be of corporate value and should be shared. Third, data integrity procedures are often quite lax for personal databases. People might not make regular backups, databases are often not secured from unauthorized access, and data validation procedures are often ignored. Fourth, often when an employee leaves the organization or moves to another role, the application and data are lost because they are not documented and the organization is unaware of their existence. Fifth, most personal databases are poorly designed and, in many cases, people use a spreadsheet as a poor substitute for a database. Personal databases are clearly very important for many organizations—when used appropriately. Data that are shared require a different processing architecture.
Client/server
The client/server architecture, in which multiple computers interact in a superior and subordinate mode, is the dominant architecture these days. A client process initiates a request and a server responds. The client is the dominant partner because it initiates the request to which the server responds. Client and server processes can run on the same computer, but generally they run on separate, linked computers. In the three-tier client/server model, the application and database are on separate servers.
A generic client/server architecture consists of several key components. It usually includes a mix of operating systems, data communications managers (usually abbreviated to DC manager), applications, clients (e.g., browser), and database management systems. The DC manager handles the transfer of data between clients and servers.
Three-tier client/server computing
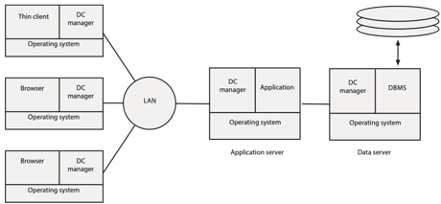
The three-tier model consists of three types of systems:
Clients perform presentation functions, manage the graphical user interface (GUI), and execute communication software that provides network access. In most cases, the client is an Internet browser, though sometimes there might be a special program, a thin client, running on the client machine.
Application servers are where the majority of the business and data logic are processed. They process commands sent by clients.
Data servers run a DBMS. They respond to requests from an application, in which case the application is a client. They will also typically provide backup and recovery services and transaction management control.
Under the three-tier model, the client requests a service from an application server, and the application server requests data from a data server. The computing environment is a complex array of clients, application servers, and data servers. An organization can spread its processing load across many servers. This enables it to scale up the data processing workload more easily. For example, if a server running several applications is overloaded, another server can be purchased and some of the workload moved to the new server.
The client/server concept has evolved to describe a widely distributed, data-rich, cooperative environment. This is known as the n-tier client/server environment, which can consist of collections of servers dedicated to applications, data, transaction management, systems management, and other tasks. It extends the database side to incorporate nonrelational systems, such as multidimensional databases, multimedia databases, and legacy systems.
Evolution of client/server computing
| Architecture | Description |
|---|---|
| Two- tier | Processing is split between client and server, which also runs the DBMS. |
| Three-tier | Client does presentation, processing is done by the server, and the DBMS is on a separate server. |
| N- tier | Client does presentation. Processing and DBMS can be spread across multiple servers. This is a distributed resources environment. |
The rise of n-tier client/server can be attributed to the benefits of adopting a component-based architecture. The goal is to build quickly scalable systems by plugging together existing components. On the client side, the Web browser is a readily available component that makes deployment of new systems very simple. When everyone in the corporation has a browser installed on their personal computer, rolling out a new application is just a case of e-mailing the URL to the people concerned. Furthermore, the flexibility of the client/server model means that smartphones and tablets can easily be incorporated into the system. Thus, the client can be an app on an iPad.
On the data server side, many data management systems already exist, either in relational format or some other data model. Middle-tier server applications can make these data available to customers through a Web client. For example, UPS was able to make its parcel tracking system available via the Web, tablet, or smartphone because the database already existed. A middle-tier was written to connect customers using a range of devices to the database.
❓ Skill builder
A European city plans to establish a fleet of two-person hybrid cars that can be rented for short periods (e.g., less than a day) for one-way trips. Potential renters first register online and then receive via the postal system a smart card that is used to gain entry to the car and pay automatically for its rental. The city also plans to have an online reservation system that renters can use to find the nearest car and reserve it. Reservations can be held for up to 30 minutes, after which time the car is released for use by other renters. Discuss the data processing architecture that you would recommend to support this venture. What technology would you need to install in each car? What technology would renters need? What features would the smart card require? Are there alternatives to a smart card?
Cloud computing
With the development of client/server computing, many organizations created data centers to contain the host of servers they needed to meet their information processing requirements. These so-called server farms can run to tens of thousands of servers. Because of security concerns, many firms are unwilling to reveal the location and size of their server farms. Google is reputed to have hundreds of thousands of servers. Many corporations run much smaller, but still significantly costly, data centers. Do they really need to run these centers?
The goal of the corporate IS unit should be to create and deploy systems that meet the operational needs of the business or give it a competitive advantage. It can gain little advantage from managing a data center. As a result, some organizations have turned to cloud computing, which is the use of shared hardware and software, to meet their processing needs. Instead of storing data and running applications on the corporate data center, applications and data are shifted to a third party data center, the cloud, which is accessed via the Internet. Companies can select from among several cloud providers. For example, it might run office applications (word processing, spreadsheet, etc.) on the Google cloud, and customer relationship management on Amazon’s cloud.
There are usually economies of scale from switching from an in-house data center to the massive shared resources of a cloud provider, which lowers the cost of information processing. As well, the IS unit can turn its attention to the systems needs of the organization, without the distraction of managing a data center.
Cloud computing vendors specialize in managing large-scale data centers. As a result, they can lower costs in some areas that might be infeasible for the typical corporation. For example, it is much cheaper to move photons through fiber optics than electrons across the electricity grid.53 This means that some cloud server farms are located where energy costs are low and minimal cooling is required. Iceland and parts of Canada are good locations for server farms because of inexpensive hydroelectric power and a cool climate. Information can be moved to and fro on a fiber optic network to be processed at a cloud site and then presented on the customer’s computer.
Cloud computing can be more than a way to save some data center management costs. It has several features, or capabilities, that have strategic implications.54 We start by looking at the levels or layers of clouds.
Cloud layers
| Layer | Description | Example |
|---|---|---|
| Infrastructure | A virtual server over which the developer has complete control | Amazon Elastic Compute Cloud (EC2) |
| Platform as a service | A developer can build a new application with the provided tools and programming language | Salesforce.com |
| Application | Access to cloud applications | Google docs |
| Collaboration | A special case of an application cloud | |
| Service | Consulting and integration services | Appirio |
As the preceding table illustrates, there a several options for the cloud customer. Someone looking to replace an office package installed on each personal computer could select an offering in the Application layer. A CIO looking to have complete control over a new application being developed from scratch could look to the infrastructure cloud, which also has the potential for high scalability.
Ownership is another way of looking at cloud offerings.55
Cloud ownership
| Type | Description |
|---|---|
| Public | A cloud provided to the general public by its owner |
| Private | A cloud restricted to an organization. It has many of the same capabilities as a public cloud but provides greater control. |
| Community | A cloud shared by several organizations to support a community project |
| Hybrid | Multiple distinct clouds sharing a standardized or proprietary technology that enables data and application portability |
Cloud capabilities
Understanding the strategic implications of cloud computing is of more interest than the layers and types because a cloud’s seven capabilities offer opportunities to address the five strategic challenges facing all organizations.
Interface control
Some cloud vendors provide their customers with an opportunity to shape the form of interaction with the cloud. Under open co-innovation, a cloud vendor has a very open and community-driven approach to services. Customers and the vendor work together to determine the roadmap for future services. Amazon follows this approach. The qualified retail model requires developers to acquire permission and be certified before releasing any new application on the vendor’s platform. This is the model Apple uses with its app store. Qualified co-innovation involves the community in the creation and maintenance of application programming interfaces (APIs). Third parties using the APIs, however, must be certified before they can be listed in the vendor’s application store. This is the model salesforce.com uses. Finally, we have the open retail model. Application developers have some influence on APIs and new features, and they are completely free to write any program on top of the system. This model is favored by Microsoft.
Location independence
This capability means that data and applications can be accessed, with appropriate permission, without needing to know the location of the resources. This capability is particularly useful for serving customers and employees across a wide variety of regions. There are some challenges to location independence. Some countries restrict where data about their citizens can be stored and who can access it.
Ubiquitous access
Ubiquity means that customers and employees can access any information service from any platform or device via a Web browser from anywhere. Some clouds are not accessible in all parts of the globe at this stage because of the lack of connectivity, sufficient bandwidth, or local restrictions on cloud computing services.
Sourcing independence
One of the attractions of cloud computing is that computing processing power becomes a utility. As a result, a company could change cloud vendors easily at low cost. It is a goal rather than a reality at this stage of cloud development.
Virtual business environments
Under cloud computing, some special needs systems can be built quickly and later abandoned. For example, in 2009 the U.S. Government had a Cash for Clunkers program that ran for a few months to encourage people to trade-in their old car for a more fuel-efficient new car. This short-lived system whose processing needs were hard to estimate was well suited to a cloud environment. No resources need be acquired, and processing power could be obtained as required.
Addressability and traceability
Traceability enables a company to track customers and employees who use an information service. Depending on the device accessing an information service, a company might be able to precisely identify the person and the location of the request. This is particularly the case with smartphones or tablets that have a GPS capability.
Rapid elasticity
Organizations cannot always judge exactly their processing needs, especially for new systems, such as the previously mentioned Cash for Clunkers program. Ideally, an organization should be able to pull on a pool of computer processing resources that it can scale up and down as required. It is often easier to scale up than down, as this is in the interests of the cloud vendor.
Strategic risk
Every firm faces five strategic risks: demand, innovation, inefficiency, scaling, and control risk.
Strategic risks
| Risk | Description |
|---|---|
| Demand | Fluctuating demand or market collapse |
| Inefficiency | Inability to match competitors’ unit costs |
| Innovation | Not innovating as well as competitors |
| Scaling | Not scaling fast and efficiently enough to meet market growth |
| Control | Inadequate procedures for acquiring or managing resources |
We now consider how the various capabilities of cloud computing are related to these risks which are summarized in a table following the discussion of each risk.
Demand risk
Most companies are concerned about loss of demand, and make extensive use of marketing techniques (e.g., advertising) to maintain and grow demand. Cloud computing can boost demand by enabling customers to access a service wherever they might be. For example, Amazon combines ubiquitous access to its cloud and the Kindle, its book reader, to permit customers to download and start reading a book wherever they have access. Addressability and traceability enable a business to learn about customers and their needs. By mining the data collected by cloud applications, a firm can learn the connections between the when, where, and what of customers’ wants. In the case of excessive demand, the elasticity of cloud resources might help a company to serve higher than expected demand.
Inefficiency risk
If a firm’s cost structure is higher than its competitors, its profit margin will be less, and it will have less money to invest in new products and services. Cloud computing offers several opportunities to reduce cost. First, location independence means it can use a cloud to provide many services to customers across a large geographic region through a single electronic service facility. Second, sourcing independence should result in a competitive market for processing power. Cloud providers compete in a way that a corporate data center does not, and competition typically drives down costs. Third, the ability to quickly create and test new applications with minimal investment in resources avoids many of the costs of procurement, installation, and the danger of obsolete hardware and software. Finally, ubiquitous access means employees can work from a wide variety of locations. For example, ubiquity enables some to work conveniently and productively from home or on the road, and thus the organization needs smaller and fewer buildings.
Innovation risk
In most industries, enterprises need to continually introduce new products and services. Even in quite stable industries with simple products (e.g., coal mining), process innovation is often important for lowering costs and delivering high quality products. The ability to modify a cloud’s interface could be of relevance to innovation. Apple’s App store restrictions might push some to Android’s more open model. As mentioned in the previous section, the capability to put up and tear down a virtual business environment quickly favors innovation because the costs of experimenting are low. Ubiquitous access makes it easier to engage customers and employees in product improvement. Customers use a firm’s products every day, and some reinvent them or use them in ways the firm never anticipated. A firm that learns of these unintended uses might identify new markets and new features that will extend sales. Addressability and traceability also enhance a firm’s ability to learn about how, when, and where customers use electronic services and network connected devices. Learning is the first step of innovation.
Scaling risk
Sometimes a new product will takeoff, and a company will struggle to meet unexpectedly high demand. If it can’t satisfy the market, competitors will move in and capture the sales that the innovator was unable to satisfy. In this case of digital products, a firm can use the cloud’s elasticity to quickly acquire new storage and processing resources. It might also take advantage of sourcing independence to use multiple clouds, another form of elasticity, to meet burgeoning demand.
Control risk
The 2008 recession clearly demonstrated the risk of inadequate controls. In some cases, an organization acquired financial resources whose value was uncertain. In others, companies lost track of what they owned because of the complexity of financial instruments and the multiple transactions involving them. A system’s interface is a point of data capture, and a well-designed interface is a control mechanism. Although it is usually not effective at identifying falsified data, it can require that certain elements of data are entered. Addressability and traceability also means that the system can record who entered the data, from which device, and when.
Cloud capabilities and strategic risks
| Risk/Capability | Demand | Inefficiency | Innovation | Scaling | Control |
|---|---|---|---|---|---|
| Interface control | ✔ | ✔ | |||
| Location independence | ✔ | ||||
| Sourcing independence | ✔ | ✔ | |||
| Virtual business environment | ✔ | ✔ | |||
| Ubiquitous access | ✔ | ✔ | ✔ | ||
| Addressability and traceability | ✔ | ✔ | ✔ | ||
| Rapid elasticity | ✔ | ✔ |
Most people think of cloud computing as an opportunity to lower costs by shifting processing from the corporate data center to a third party. More imaginative thinkers will see cloud computing as an opportunity to gain a competitive advantage.
Distributed database
The client/server architecture is concerned with minimizing processing costs by distributing processing between multiple clients and servers. Another factor in the total processing cost equation is communication. The cost of transmitting data usually increases with distance, and there can be substantial savings by locating a database close to those most likely to use it. The trade-off for a distributed database is lowered communication costs versus increased complexity. While the Internet and fiber optics have lowered the costs of communication, for a globally distributed organization data transmission costs can still be an issue because many countries still lack the bandwidth found in advanced economies.
Distributed database architecture describes the situation where a database is in more than one location but still accessible as if it were centrally located. For example, a multinational organization might locate its Indonesian data in Jakarta, its Japanese data in Tokyo, and its Australian data in Sydney. If most queries deal with the local situation, communication costs are substantially lower than if the database were centrally located. Furthermore, since the database is still treated as one logical entity, queries that require access to different physical locations can be processed. For example, the query “Find total sales of red hats in Australia” is likely to originate in Australia and be processed using the Sydney part of the database. A query of the form “Find total sales of red hats” is more likely to come from a headquarters’ user and is resolved by accessing each of the local databases, though the user need not be aware of where the data are stored because the database appears as a single logical entity.
A distributed database management system (DDBMS) is a federation of individual DBMSs. Each site has a local DBMS and DC manager. In many respects, each site acts semi-independently. Each site also contains additional software that enables it to be part of the federation and act as a single database. It is this additional software that creates the DDBMS and enables the multiple databases to appear as one.
A DDBMS introduces a need for a data store containing details of the entire system. Information must be kept about the structure and location of every database, table, row, and column and their possible replicas. The system catalog is extended to include such information. The system catalog must also be distributed; otherwise, every request for information would have to be routed through some central point. For instance, if the systems catalog were stored in Tokyo, a query on Sydney data would first have to access the Tokyo-based catalog. This would create a bottleneck.
A hybrid, distributed architecture
Any organization of a reasonable size is likely to have a mix of the data processing architectures. Databases will exist on stand-alone personal computers, multiple client/server networks, distributed mainframes, clouds, and so on. Architectures continue to evolve because information technology is dynamic. Today’s best solutions for data processing can become obsolete very quickly. Yet, organizations have invested large sums in existing systems that meet their current needs and do not warrant replacement. As a result, organizations evolve a hybrid architecture—a mix of the various forms. The concern of the IS unit is how to patch this hybrid together so that clients see it as a seamless system that readily provides needed information. In creating this ideal system, there are some underlying key concepts that should be observed. These fundamental principles were initially stated in terms of a distributed database. However, they can be considered to apply broadly to the evolving, hybrid architecture that organizations must continually fashion.
The fundamental principles of a hybrid architecture
| Principle |
|---|
| Transparency |
| No reliance on a central site |
| Local autonomy |
| Continuous operation |
| Distributed query processing |
| Distributed transaction processing |
| Fragmentation independence |
| Replication independence |
| Hardware independence |
| Operating system independence |
| Network independence |
| DBMS independence |
Transparency
The user should not have to know where data are stored nor how they are processed. The location of data, its storage format, and access method should be invisible to the client. The system should accept queries and resolve them expeditiously. Of course, the system should check that the person is authorized to access the requested data. Transparency is also known as location independence—the system can be used independently of the location of data.
No reliance on a central site
Reliance on a central site for management of a hybrid architecture creates two major problems. First, because all requests are routed through the central site, bottlenecks develop during peak periods. Second, if the central site fails, the entire system fails. A controlling central site is too vulnerable, and control should be distributed throughout the system.
Local autonomy
A high degree of local autonomy avoids dependence on a central site. Data are locally owned and managed. The local site is responsible for the security, integrity, and storage of local data. There cannot be absolute local autonomy because the various sites must cooperate in order for transparency to be feasible. Cooperation always requires relinquishing some autonomy.
Continuous operation
The system must be accessible when required. Since business is increasingly global and clients are geographically dispersed, the system must be continuously available. Many data centers now describe their operations as “24/7” (24 hours a day and 7 days a week). Clouds must operate continuously.
Distributed query processing
The time taken to execute a query should be generally independent of the location from which it is submitted. Deciding the most efficient way to process the query is the system’s responsibility, not the client’s. For example, a Sydney analyst could submit the query, “Find sales of winter coats in Japan.” The system is responsible for deciding which messages and data to send between the various sites where tables are located.
Distributed transaction processing
In a hybrid system, a single transaction can require updating of multiple files at multiple sites. The system must ensure that a transaction is successfully executed for all sites. Partial updating of files will cause inconsistencies.
Fragmentation independence
Fragmentation independence means that any table can be broken into fragments and then stored in separate physical locations. For example, the sales table could be fragmented so that Indonesian data are stored in Jakarta, Japanese data in Tokyo, and so on. A fragment is any piece of a table that can be created by applying restriction and projection operations. Using join and union, fragments can be assembled to create the full table. Fragmentation is the key to a distributed database. Without fragmentation independence, data cannot be distributed.
Replication independence
Fragmentation is good when local data are mainly processed locally, but there are some applications that also frequently process remote data. For example, the New York office of an international airline may need both American (local) and European (remote) data, and its London office may need American (remote) and European (local) data. In this case, fragmentation into American and European data may not substantially reduce communication costs.
Replication means that a fragment of data can be copied and physically stored at multiple sites; thus the European fragment could be replicated and stored in New York, and the American fragment replicated and stored in London. As a result, applications in both New York and London will reduce their communication costs. Of course, the trade-off is that when a replicated fragment is updated, all copies also must be updated. Reduced communication costs are exchanged for increased update complexity.
Replication independence implies that replication happens behind the scenes. The client is oblivious to replication and requires no knowledge of this activity.
There are two major approaches to replication: synchronous or asynchronous updates. Synchronous replication means all databases are updated at the same time. Although this is ideal, it is not a simple task and is resource intensive. Asynchronous replication occurs when changes made to one database are relayed to other databases within a certain period established by the database administrator. It does not provide real-time updating, but it takes fewer IS resources. Asynchronous replication is a compromise strategy for distributed DBMS replication. When real-time updating is not absolutely necessary, asynchronous replication can save IS resources.
Hardware independence
A hybrid architecture should support hardware from multiple suppliers without affecting the users’ capacity to query files. Hardware independence is a long-term goal of many IS managers. With virtualization, under which a computer can run another operating system, hardware independence has become less of an issue. For example, a Macintosh can run OS X (the native system), a variety of Windows operating systems, and many variations of Linux.
Operating system independence
Operating system independence is another goal much sought after by IS executives. Ideally, the various DBMSs and applications of the hybrid system should work on a range of operating systems on a variety of hardware. Browser-based systems are a way of providing operating system independence.
Network independence
Clearly, network independence is desired by organizations that wish to avoid the electronic shackles of being committed to any single hardware or software supplier.
DBMS independence
The drive for independence is contagious and has been caught by the DBMS as well. Since SQL is a standard for relational databases, organizations may well be able to achieve DBMS independence. By settling on the relational model as the organizational standard, ensuring that all DBMSs installed conform to this model, and using only standard SQL, an organization may approach DBMS independence. Nevertheless, do not forget all those old systems from the pre-relational days—a legacy that must be supported in a hybrid architecture.
Organizations can gain considerable DBMS independence by using Open Database Connectivity (ODBC) technology, which was covered earlier in the chapter on SQL. An application that uses the ODBC interface can access any ODBC-compliant DBMS. In a distributed environment, such as an n-tier client/server, ODBC enables application servers to access a variety of vendors’ databases on different data servers.
Conclusion—paradise postponed
For data managers, the 12 principles just outlined are ideal goals. In the hurly-burly of everyday business, incomplete information, and an uncertain future, data managers struggle valiantly to meet clients’ needs with a hybrid architecture that is an imperfect interpretation of IS paradise. It is unlikely that these principles will ever be totally achieved. They are guidelines and something to reflect on when making the inevitable trade-offs that occur in data management.
Now that you understand the general goals of a distributed database architecture, we will consider the major aspects of the enabling technology. First, we will look at distributed data access methods and then distributed database design. In keeping with our focus on the relational model, illustrative SQL examples are used.
Distributed data access
When data are distributed across multiple locations, the data management logic must be adapted to recognize multiple locations. The various types of distributed data access methods are considered, and an example is used to illustrate the differences between the methods.
Remote request
A remote request occurs when an application issues a single data request
to a single remote site. Consider the case of a branch bank requesting
data for a specific customer from the bank’s central server located in
Atlanta. The SQL command specifies the name of the server (atlserver),
the database (bankdb), and the name of the table (customer).
A remote request can extract a table from the database for processing on the local database. For example, the Athens branch may download balance details of customers at the beginning of each day and handle queries locally rather than issuing a remote request. The SQL is
Remote transaction
Multiple data requests are often necessary to execute a complete business transaction. For example, to add a new customer account might require inserting a row in two tables: one row for the account and another row in the table relating a customer to the new account. A remote transaction contains multiple data requests for a single remote location. The following example illustrates how a branch bank creates a new customer account on the central server:
BEGIN WORK;
INSERT INTO atlserver.bankdb.account
(accnum, acctype)
VALUES (789, 'C');
INSERT INTO atlserver.bankdb.cust_acct
(custnum, accnum)
VALUES (123, 789);
COMMIT WORK;The commands BEGIN WORK and COMMIT WORK surround the SQL commands necessary to complete the transaction. The transaction is successful only if both SQL statements are successfully executed. If one of the SQL statements fails, the entire transaction fails.
Distributed transaction
A distributed transaction supports multiple data requests for data at multiple locations. Each request is for data on a single server. Support for distributed transactions permits a client to access tables on different servers.
Consider the case of a bank that operates in the United States and Norway and keeps details of employees on a server in the country in which they reside. The following example illustrates a revision of the database to record details of an employee who moves from the United States to Norway. The transaction copies the data for the employee from the Atlanta server to the Oslo server and then deletes the entry for that employee on the Atlanta server.
BEGIN WORK;
INSERT INTO osloserver.bankdb.employee
(empcode, emplname, …)
SELECT empcode, emplname, …
FROM atlserver.bankdb.employee
WHERE empcode = 123;
DELETE FROM atlserver.bankdb.employee
WHERE empcode = 123;
COMMIT WORK;As in the case of the remote transaction, the transaction is successful only if both SQL statements are successfully executed.
Distributed request
A distributed request is the most complicated form of distributed data access. It supports processing of multiple requests at multiple sites, and each request can access data on multiple sites. This means that a distributed request can handle data replicated or fragmented across multiple servers.
Let’s assume the bank has had a good year and decided to give all employees a 15 percent bonus based on their annual salary and add USD 1,000 or NOK 7,500 to their retirement account, depending on whether the employee is based in the United States or Norway.
BEGIN WORK;
CREATE VIEW temp
(empcode, empfname, emplname, empsalary)
AS
SELECT empcode, empfname, emplname, empsalary
FROM atlserver.bankdb.employee
UNION
SELECT empcode, empfname, emplname, empsalary
FROM osloserver.bankdb.employee;
SELECT empcode, empfname, emplname, empsalary*.15 AS bonus
FROM temp;
UPDATE atlserver.bankdb.employee
SET empusdretfund = empusdretfund + 1000;
UPDATE osloserver.bankdb.employee
SET empkrnretfund = empkrnretfund + 7500;
COMMIT WORK;The transaction first creates a view containing all employees by a union on the employee tables for both locations. This view is then used to calculate the bonus. Two SQL update commands then update the respective retirement fund records of the U.S. and Norwegian employees. Notice that retirement funds are recorded in U.S. dollars or Norwegian kroner.
Ideally, a distributed request should not require the application to know where data are physically located. A DDBMS should not require the application to specify the name of the server. So, for example, it should be possible to write the following SQL:
It is the responsibility of the DDBMS to determine where data are stored. In other words, the DDBMS is responsible for ensuring data location and fragmentation transparency.
Distributed database design
Designing a distributed database is a two-stage process. First, develop a data model using the principles discussed in Section 2. Second, decide how data and processing will be distributed by applying the concepts of partitioning and replication. Partitioning is the fragmentation of tables across servers. Tables can be fragmented horizontally, vertically, or by some combination of both. Replication is the duplication of tables across servers.
Horizontal fragmentation
A table is split into groups of rows when horizontally fragmented. For example, a firm may fragment its employee table into three because it has employees in Tokyo, Sydney, and Jakarta and store the fragment on the appropriate DBMS server for each city.
Horizontal fragmentation
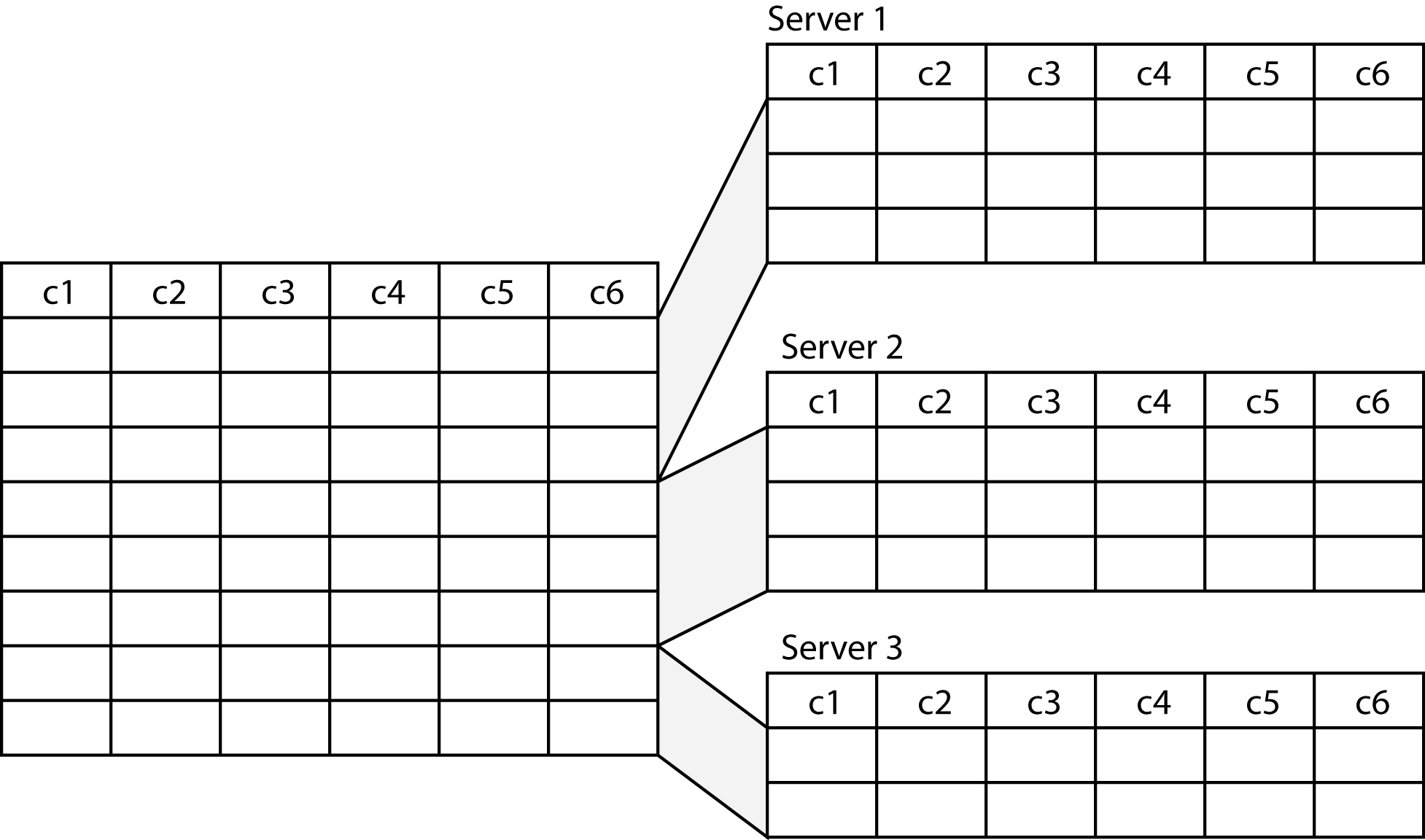
Three separate employee tables would be defined. Each would have a different name (e.g., emp-syd) but exactly the same columns. To insert a new employee, the SQL code is
Vertical fragmentation
When vertically fragmented, a table is split into columns. For example, a firm may fragment its employee table vertically to spread the processing load across servers. There could be one server to handle address lookups and another to process payroll. In this case, the columns containing address information would be stored on one server and payroll columns on the other server. Notice that the primary key column (c1) must be stored on both servers; otherwise, the entity integrity rule is violated.
Vertical fragmentation
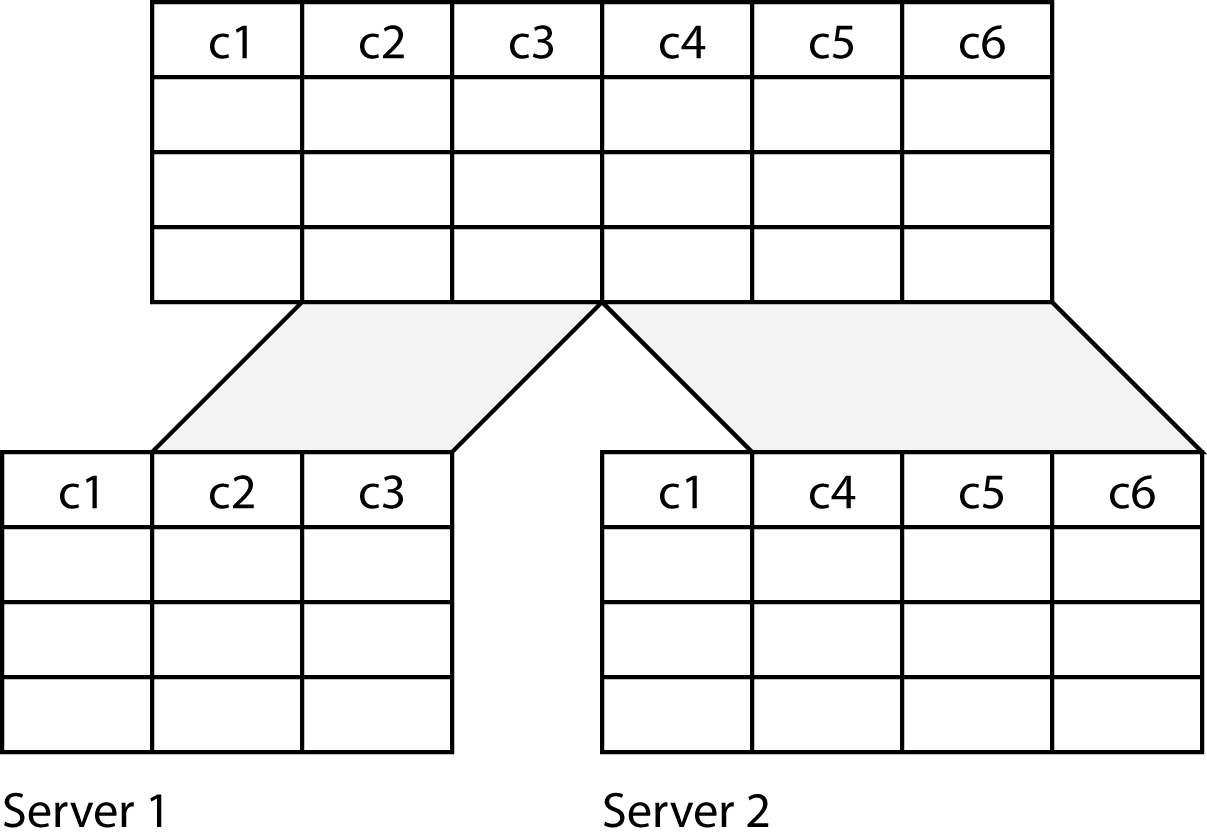
Hybrid fragmentation
Hybrid fragmentation is a mixture of horizontal and vertical. For example, the employee table could be first horizontally fragmented to distribute the data to where employees are located. Then, some of the horizontal fragments could be vertically fragmented to split processing across servers. Thus, if Tokyo is the corporate headquarters with many employees, the Tokyo horizontal fragment of the employee database could be vertically fragmented so that separate servers could handle address and payroll processing.
Horizontal fragmentation distributes data and thus can be used to reduce communication costs by storing data where they are most likely to be needed. Vertical fragmentation is used to distribute data across servers so that the processing load can be distributed. Hybrid fragmentation can be used to distribute both data and applications across servers.
Replication
Under replication, tables can be fully or partly replicated. Full replication means that tables are duplicated at each of the sites. The advantages of full replication are greater data integrity (because replication is essentially mirroring) and faster processing (because it can be done locally). However, replication is expensive because of the need to synchronize inserts, updates, and deletes across the replicated tables. When one table is altered, all the replicas must also be modified. A compromise is to use partial replication by duplicating the indexes only. This will increase the speed of query processing. The index can be processed locally, and then the required rows retrieved from the remote database.
❓ Skill builder
A company supplies pharmaceuticals to sheep and cattle stations in outback Australia. Its agents often visit remote areas and are usually out of reach of a mobile phone network. To advise station owners, what data management strategy would you recommend for the company?
Conclusion
The two fundamental skills of data management, data modeling and data querying, are not changed by the development of a distributed data architecture such as client/server and the adoption of cloud computing. Data modeling remains unchanged. A high-fidelity data model is required regardless of where data are stored and whichever architecture is selected. SQL can be used to query local, remote, and distributed databases. Indeed, the adoption of client/server technology has seen a widespread increase in the demand for SQL skills.
Summary
Data can be stored and processed locally or remotely. Combinations of these two options provide the basic architecture options: remote job entry, personal database, and client/server. Many organizations are looking to cloud computing to reduce the processing costs and to allow them to focus on building systems. Cloud computing can also provide organizations with a competitive advantage if they exploit its seven capabilities to reduce one or more of the strategic risks.
Under distributed database architecture, a database is in more than one location but still accessible as if it were centrally located. The trade-off is lowered communication costs versus increased complexity. A hybrid architecture is a mix of data processing architectures. The concern of the IS department is to patch this hybrid together so that clients see a seamless system that readily provides needed information. The fundamental principles that a hybrid architecture should satisfy are transparency, no reliance on a central site, local autonomy, continuous operation, distributed query processing, distributed transaction processing, fragmentation independence, replication independence, hardware independence, operating system independence, network independence, and DBMS independence.
There are four types of distributed data access. In order of complexity, these are remote request, remote transaction, distributed transaction, and distributed request.
Distributed database design is based on the principles of fragmentation and replication. Horizontal fragmentation splits a table by rows and reduces communication costs by placing data where they are likely to be required. Vertical fragmentation splits a table by columns and spreads the processing load across servers. Hybrid fragmentation is a combination of horizontal and vertical fragmentation. Replication is the duplication of identical tables at different sites. Partial replication involves the replication of indexes. Replication speeds up local processing at the cost of maintaining the replicas.
Key terms and concepts
| Application server | Hybrid architecture |
| Client/server | Hybrid fragmentation |
| Cloud computing | Local autonomy |
| Continuous operation | Mainframe |
| Data communications manager (DC) | N-tier architecture |
| Data processing | Network independence |
| Data server | Personal database |
| Data storage | Remote job entry |
| Database architecture | Remote request |
| Database management system (DBMS) | Remote transaction |
| DBMS independence | Replication |
| DBMS server | Replication independence |
| Distributed data access | Server |
| Distributed database | Software independence |
| Distributed query processing | Strategic risk |
| Distributed request | Supercomputer |
| Distributed transaction | Three-tier architecture |
| Distributed transaction processing | Transaction processing monitor |
| Fragmentation independence | Transparency |
| Hardware independence | Two-tier architecture |
| Horizontal fragmentation | Vertical fragmentation |
References and additional readings
Child, J. (1987). Information technology, organizations, and the response to strategic challenges. California Management Review, 30(1), 33-50.
Iyer, B., & Henderson, J. C. (2010). Preparing for the future: understanding the seven capabilities of cloud computing. MISQ Executive, 9(2), 117-131.
Watson, R. T., Wynn, D., & Boudreau, M.-C. (2005). JBoss: The evolution of professional open source software. MISQ Executive, 4(3), 329-341.
Exercises
How does client/server differ from cloud computing?
In what situations are you likely to use remote job entry?
What are the disadvantages of personal databases?
What is a firm likely to gain when it moves from a centralized to a distributed database? What are the potential costs?
In terms of a hybrid architecture, what does transparency mean?
In terms of a hybrid architecture, what does fragmentation independence mean?
In terms of a hybrid architecture, what does DBMS independence mean?
How does ODBC support a hybrid architecture?
A university professor is about to develop a large simulation model for describing the global economy. The model uses data from 65 countries to simulate alternative economic policies and their possible outcomes. In terms of volume, the data requirements are quite modest, but the mathematical model is very complex, and there are many equations that must be solved for each quarter the model is run. What data processing/data storage architecture would you recommend?
A multinational company has operated relatively independent organizations in 15 countries. The new CEO wants greater coordination and believes that marketing, production, and purchasing should be globally managed. As a result, the corporate IS department must work with the separate national IS departments to integrate the various national applications and databases. What are the implications for the corporate data processing and database architecture? What are the key facts you would like to know before developing an integration plan? What problems do you anticipate? What is your intuitive feeling about the key features of the new architecture?
A university wants to teach a specialized data management topic to its students every semester. It will take about two weeks to cover the topic, and during this period students will need access to a small high performance computing cluster on which the necessary software is installed. The software is Linux-based. Investigate three cloud computing offerings and make a recommendation as to which one the university should use.
The further electrons are moved, the more energy is lost. As much as a third of the initial energy generated can be lost during transmission across the grid before it gets to the final customer.↩︎
This section is based on Iyer, B., & Henderson, J. C. (2010). Preparing for the future: understanding the seven capabilities of cloud computing MIS Executive, 9(2), 117-131.↩︎
Mell, P., & Grance, T. (2009). The NIST definition of cloud computing: National Institute of Standards and Technology.↩︎